7 Constructing the next wave of the history match: point generation
Having generated emulators based on wave0 data, evaluated their suitability, and considered a means by which to rule out parameter sets, we can now produce a new set of parameter sets to pass to the model.
This section is divided in two parts:
We first see how to generate new sets of parameters (which will be used to train wave 1 emulators);
We then compare the performance of the initial parameter sets with the new parameter sets. In other words, we ask: do the model outputs at the new parameter sets match the observations better than the model outputs at the initial parameter sets?
7.1 Generating sets of parameters for the next wave
The function generate_new_design is designed to generate new sets of parameters; its default behaviour is as follows.
- If prior parameter sets are provided, step 1 is skipped, otherwise a set is generated using a Latin Hypercube Design, rejecting implausible parameter sets.
- Pairs of parameter sets are selected at random and more sets are sampled from lines connecting them, with particular importance given to those that are close to the non-implausible boundary;
- Using these as seeding points, more parameter sets are generated using importance sampling to attempt to fully cover the non-implausible region.
All of these steps can be overridden or modified, but the default behaviour allows for a good rudimentary search of the non-implausible space.
points_1 <- generate_new_design(ems0, 120, targets, measure.method = 'maximin')
plot(points_1, pch = 16, cex = 0.5)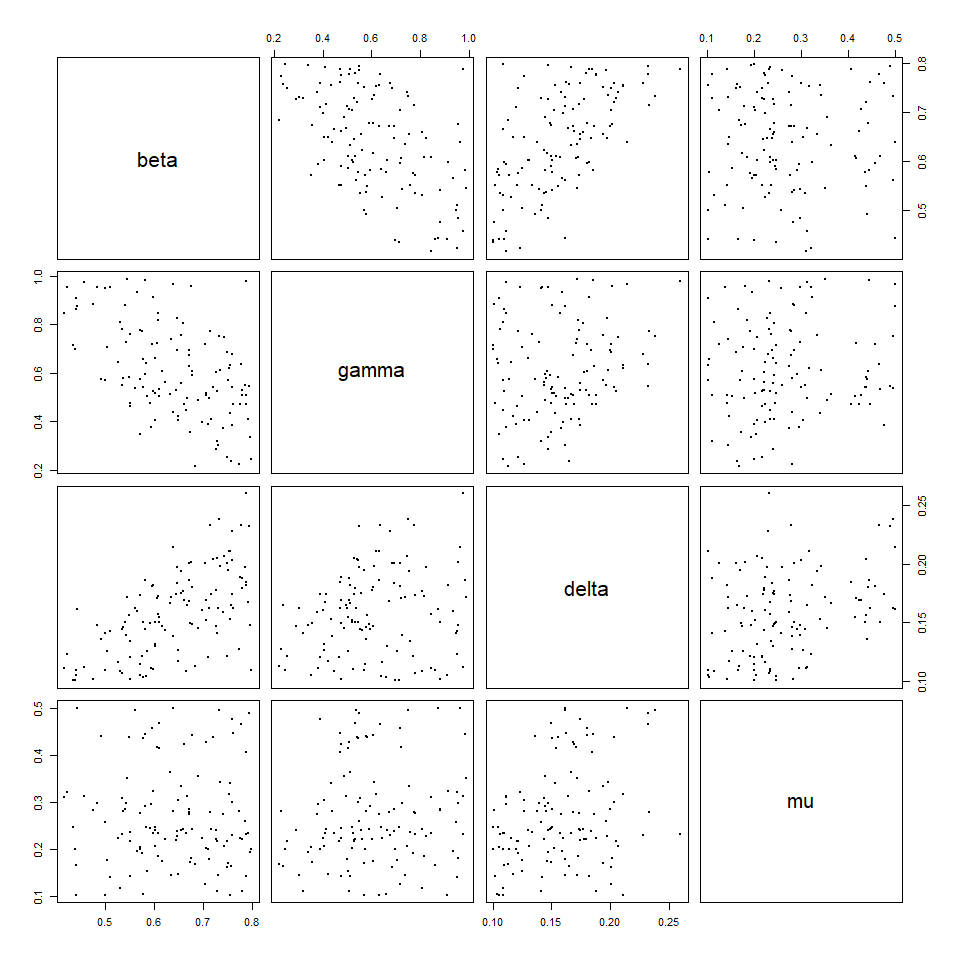
We can start to see the structure of the non-implausible region, here. The wave_points function provides a better indication of the difference between the two sets of wave data.

Here wave0 parameter sets are in yellow and points_1 (i.e. new parameter sets) are in purple. The plots in the main diagonal show the distribution of parameter sets in wave0 and that of points_1.
7.2 Comparing new and old parameter sets
Now we can put points_1 into the model and obtain the model outputs:
Binding together points_1 and points_1_outputs we obtain wave1, the full data for the next wave.
We can see how much better the wave1 parameter sets perform compared to the original wave0 parameter sets using simulator_plot.
wave1 <- data.frame(cbind(points_1,points_1_outputs))%>%
setNames(c(names(ranges),paste0("I",seq(10,30,by=5)), paste0("EV",seq(10,30,by=5))))
all_points <- list(wave0[1:9], wave1[1:9])
simulator_plot(all_points, targets, palette=c("goldenrod1", "red"))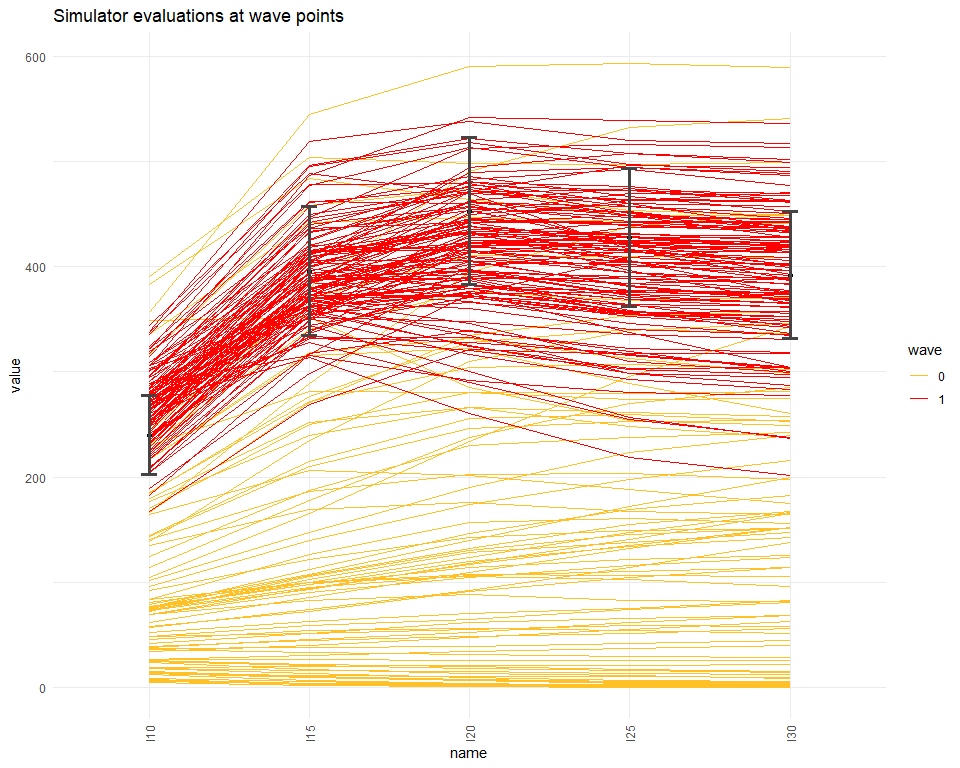
We can see that, compared to the space-filling random parameter sets used to train the first emulators, the new parameter sets are in closer agreement with our targets. Subsequent waves, trained on these new parameter sets, will be more confident in the new non-implausible region and will therefore refine the region in light of the greater certainty.