9 Second wave
A video presentation of this section can be found here.
new_points tend to lie in a small region inside the original input space, we will train the new emulators only on the non-implausible region found in wave one. This can be done simply setting the argument check.ranges to TRUE in the function emulator_from_data.
It is a good strategy to increase the number of repetitions used at each wave: this, paired with the fact later waves emulators are trained on a reduced space, allows to create more and more precise emulators. Using this principle, we run the model \(50\) times on each parameter set in new_points (for the first wave we used \(25\) repetitions). We then bind all results to create a dataframe wave1 and we split this into two subsets, new_all_training to train the new emulators and new_all_valid to validate them. We select the first 5000 rows (corresponding to the first 100 parameter sets in new_points) for the training data and the last 2500 (corresponding to the last 50 parameter sets in new_points) for the validation data.
new_results <- list()
with_progress({
p <- progressor(nrow(initial_points))
for (i in 1:nrow(new_points)) {
model_out <- get_results(unlist(new_points[i,]), nreps = 50, outs = c("I", "R"),
times = c(25, 40, 100, 200))
new_results[[i]] <- model_out
p(message = sprintf("Run %g", i))
}
})
wave1 <- data.frame(do.call('rbind', new_results))
new_all_training <- wave1[1:5000,]
new_all_valid <- wave1[5001:7500,]To train new emulators we use emulator_from_data, passing the new training data, the outputs names and the initial ranges of the parameters. We also set check.ranges to TRUE to ensure that the new emulators are trained only on the non-implausible region found in wave one, and emulator_type = ‘variance’ to indicate that we want to train stochastic emulators.
new_stoch_emulators <- emulator_from_data(new_all_training, output_names, ranges,
check.ranges=TRUE, emulator_type = 'variance')As usual, before using the obtained emulators, we need to check their diagnostics. We use the function validation_diagnostics which takes the new emulators, the targets and the new validation data:
vd <- validation_diagnostics(new_stoch_emulators, targets, new_all_valid, plt=TRUE, row=2)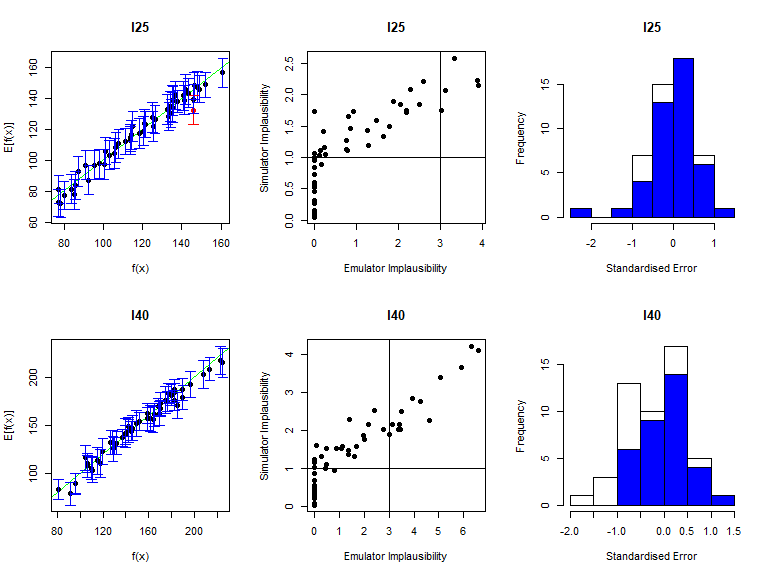
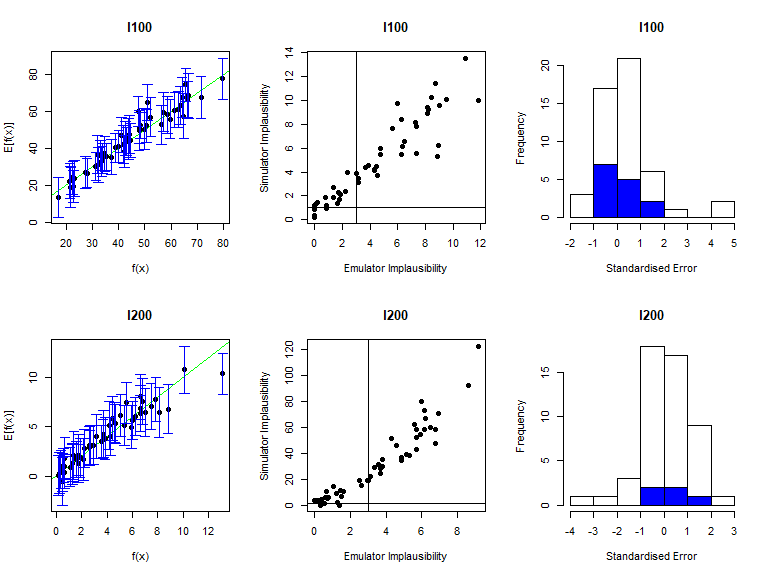
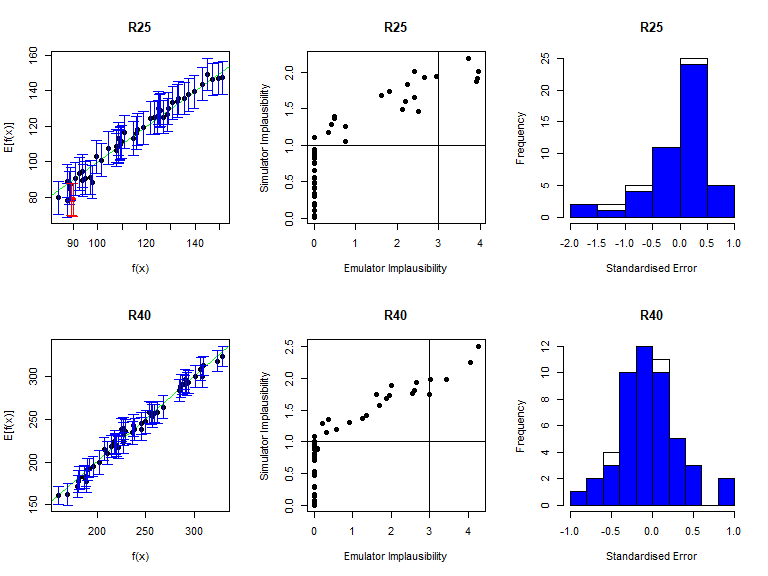
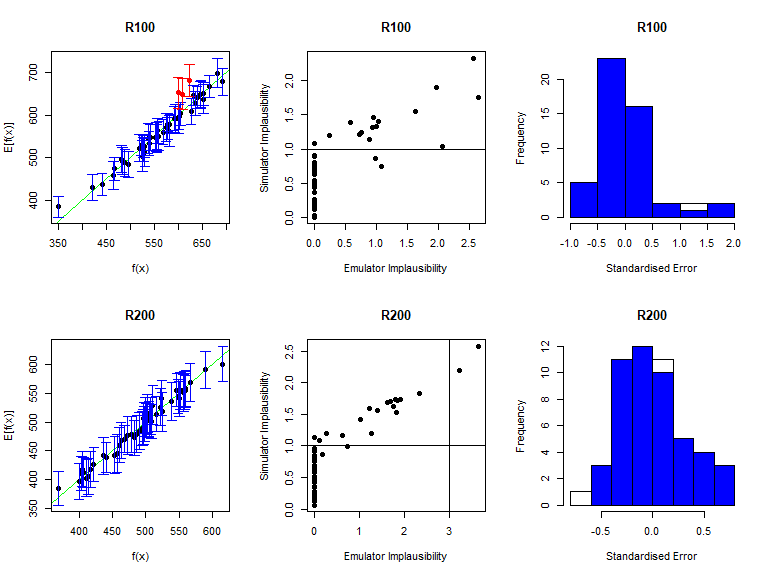
Since these diagnostics look good, we can generate new non-implausible points. Here is the second caveat: we now need to pass both new_stoch_emulators and stoch_emulators to the generate_new_design function, since a point needs to be non-implausible for all emulators trained so far, and not just for emulators trained in the current wave:
new_new_points <- generate_new_design(c(new_stoch_emulators, stoch_emulators), 150, targets)Below we run the model on the points provided by the second wave of history matching:
new_new_results <- list()
with_progress({
p <- progressor(nrow(initial_points))
for (i in 1:nrow(new_new_points)) {
model_out <- get_results(unlist(new_new_points[i,]), nreps = 100, outs = c("I", "R"),
times = c(25, 40, 100, 200))
new_new_results[[i]] <- model_out
p(message = sprintf("Run %g", i))
}
})
wave2 <- data.frame(do.call('rbind', new_new_results))
new_new_all_training <- wave2[1:10000,]