10 Second wave
In this section we move to the second wave of emulation. We will start by defining all the data necessary to train the second wave of emulators. We will then go through the same steps as in the previous section to train the emulators, test them and generate new points.
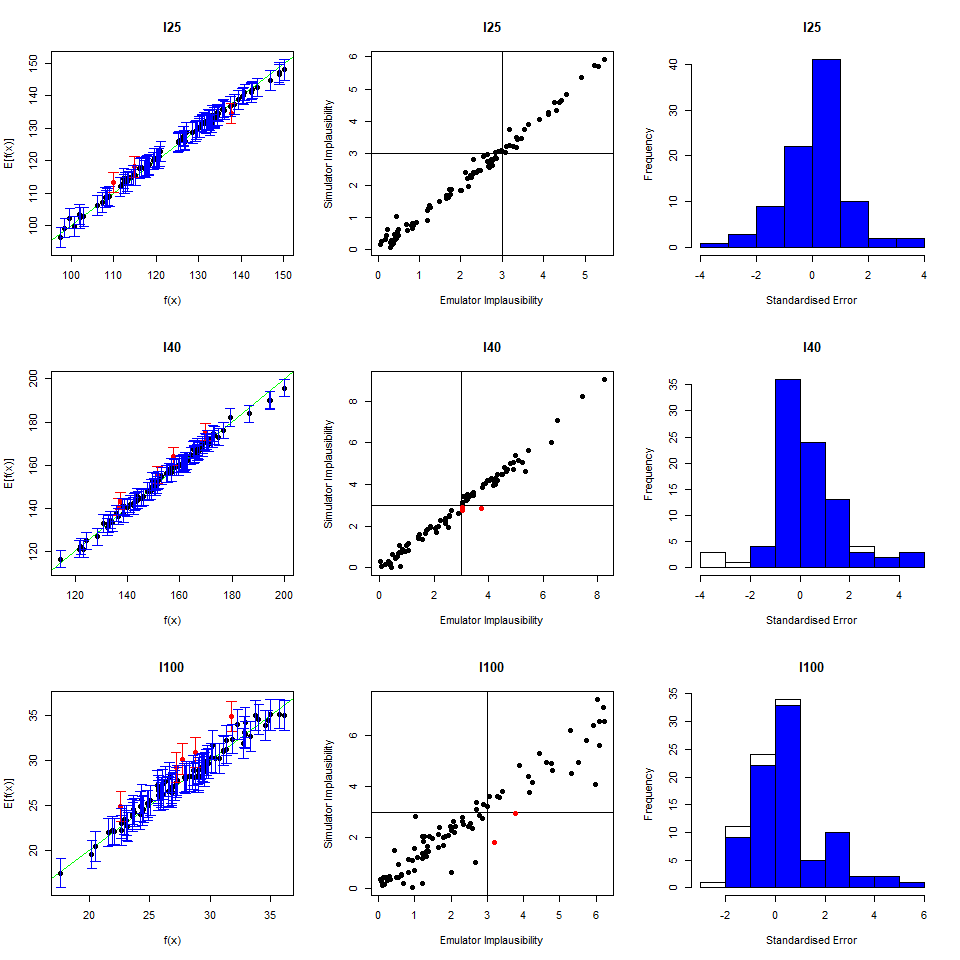
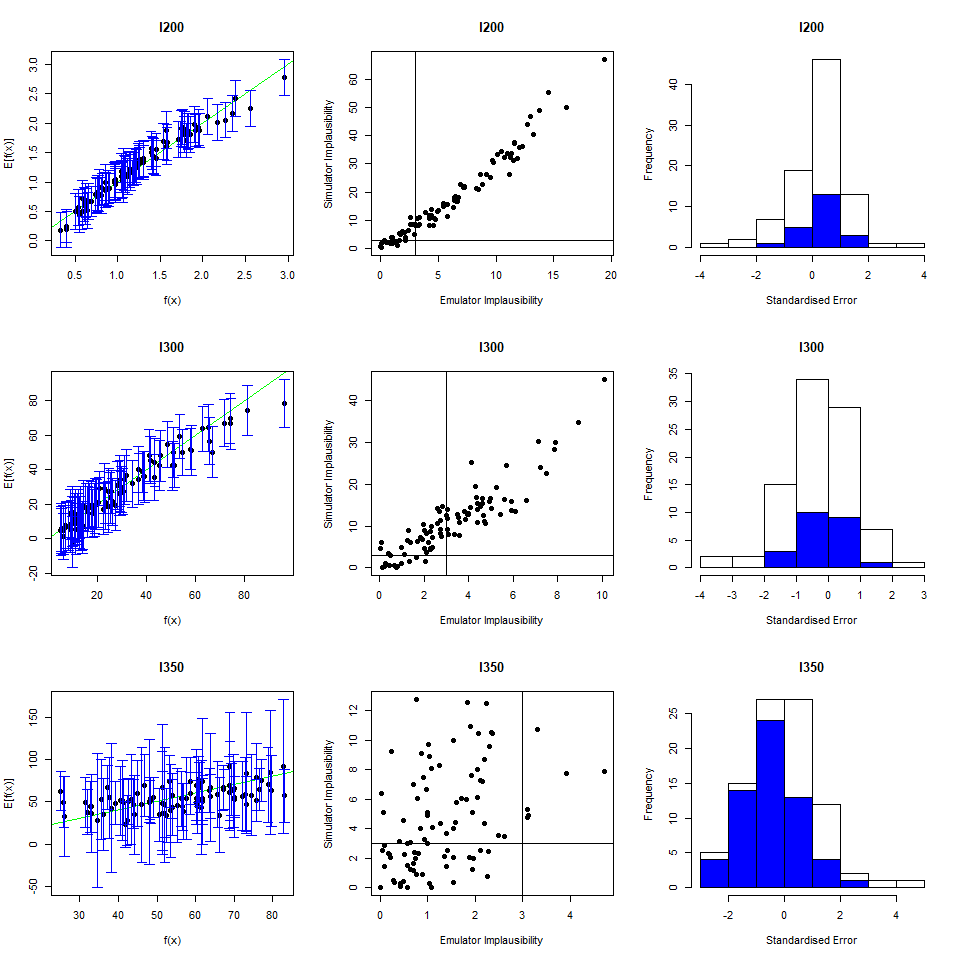
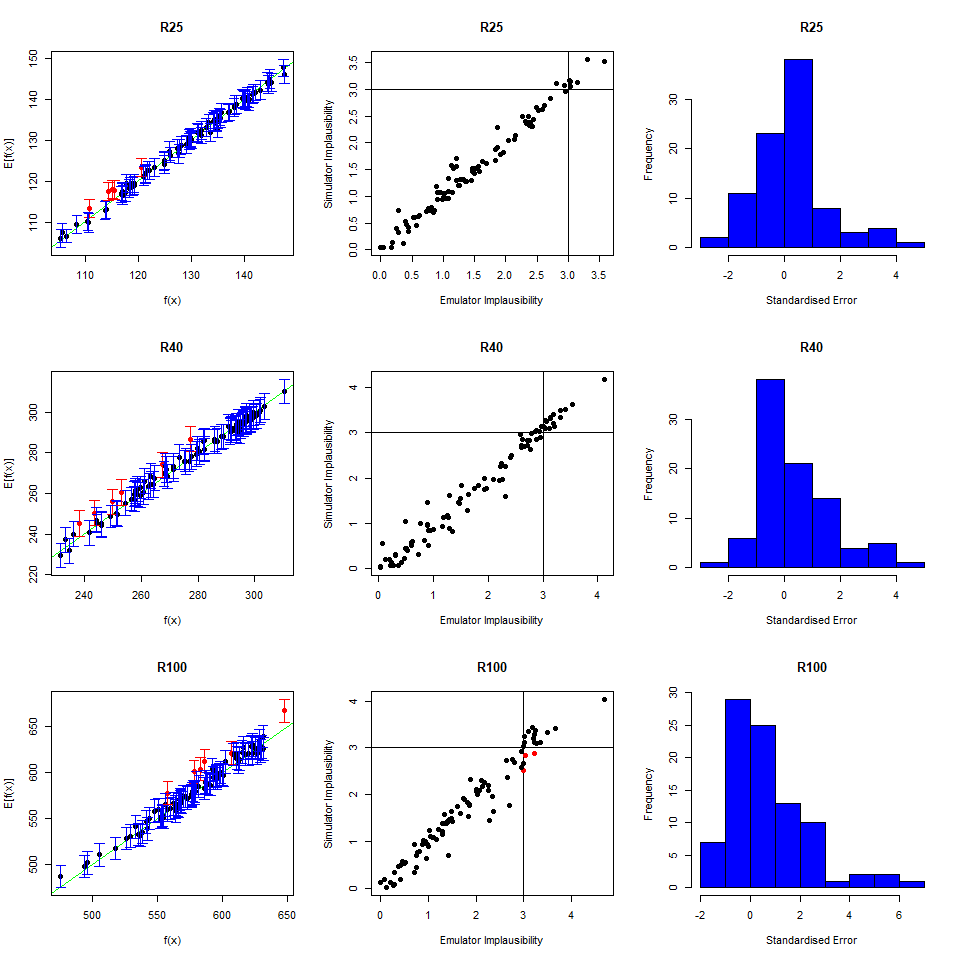
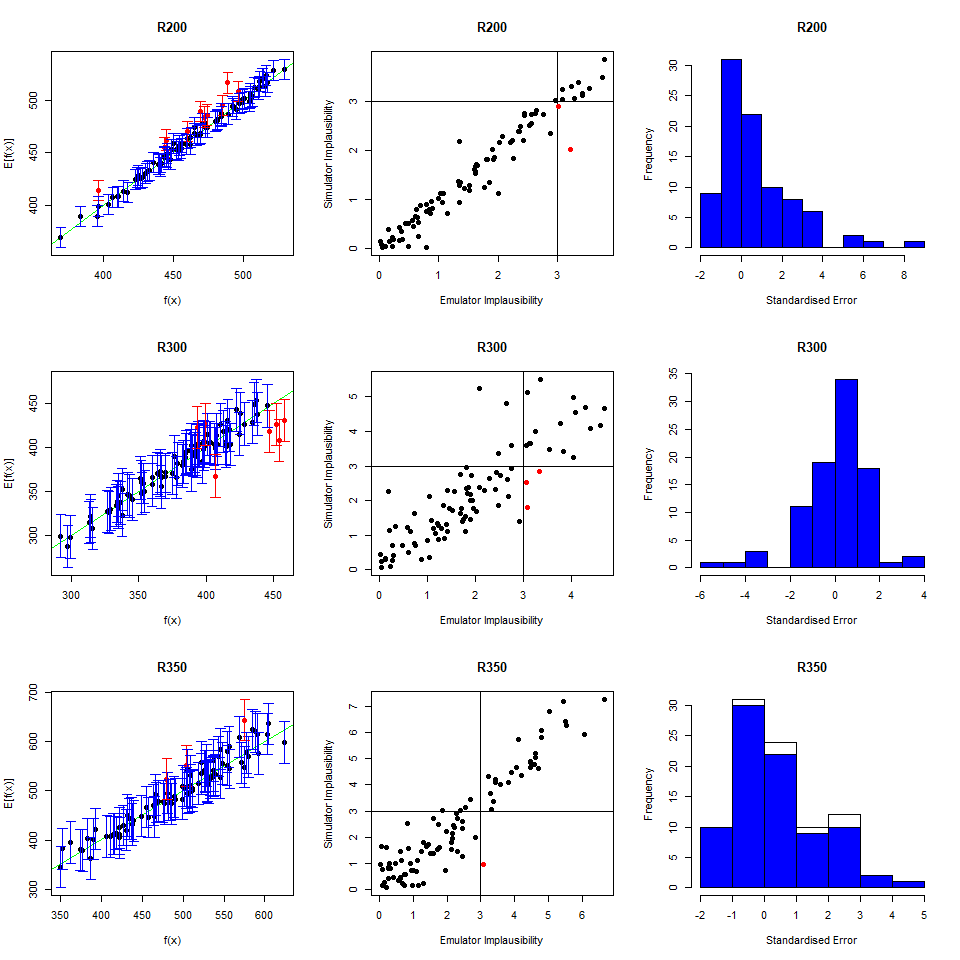
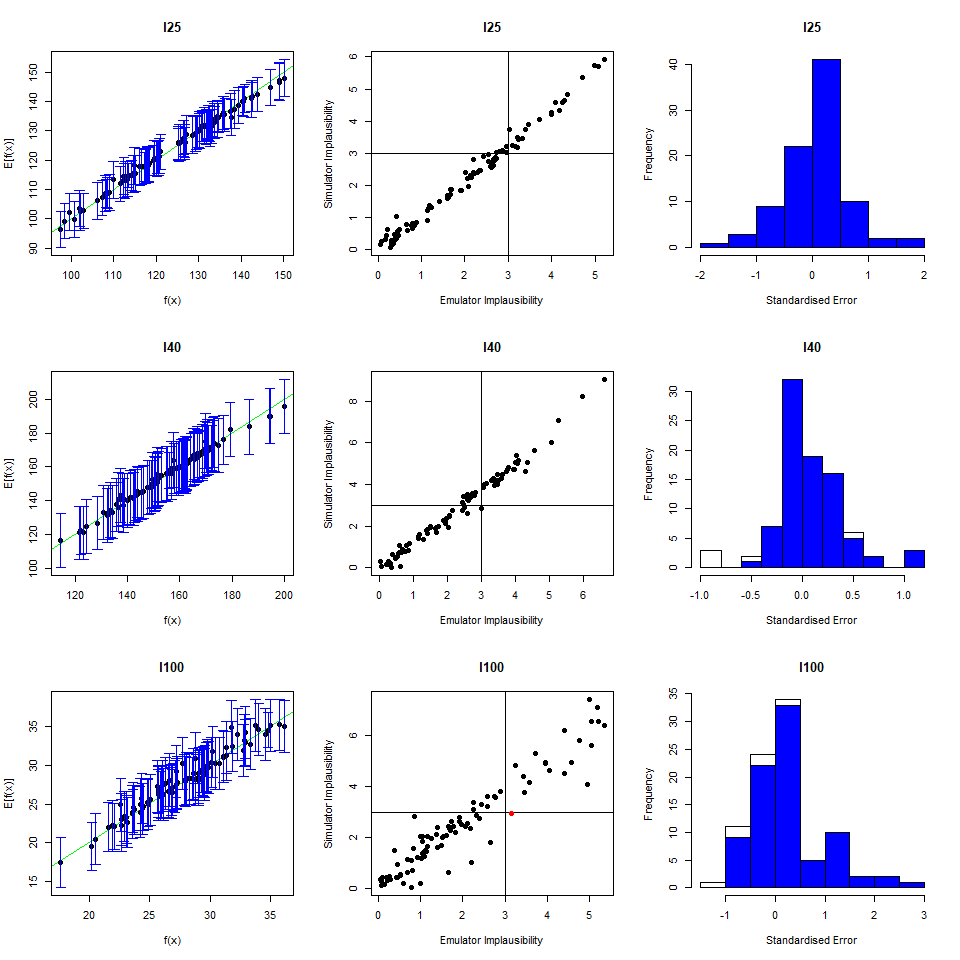
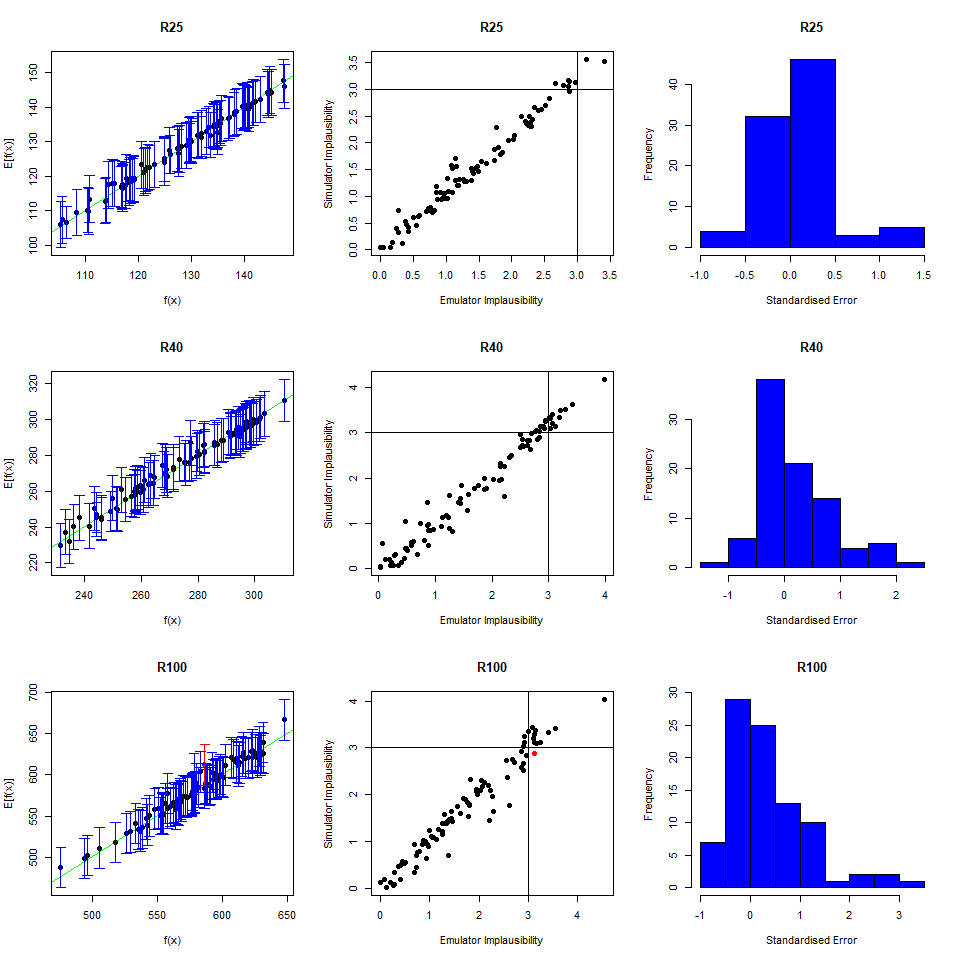
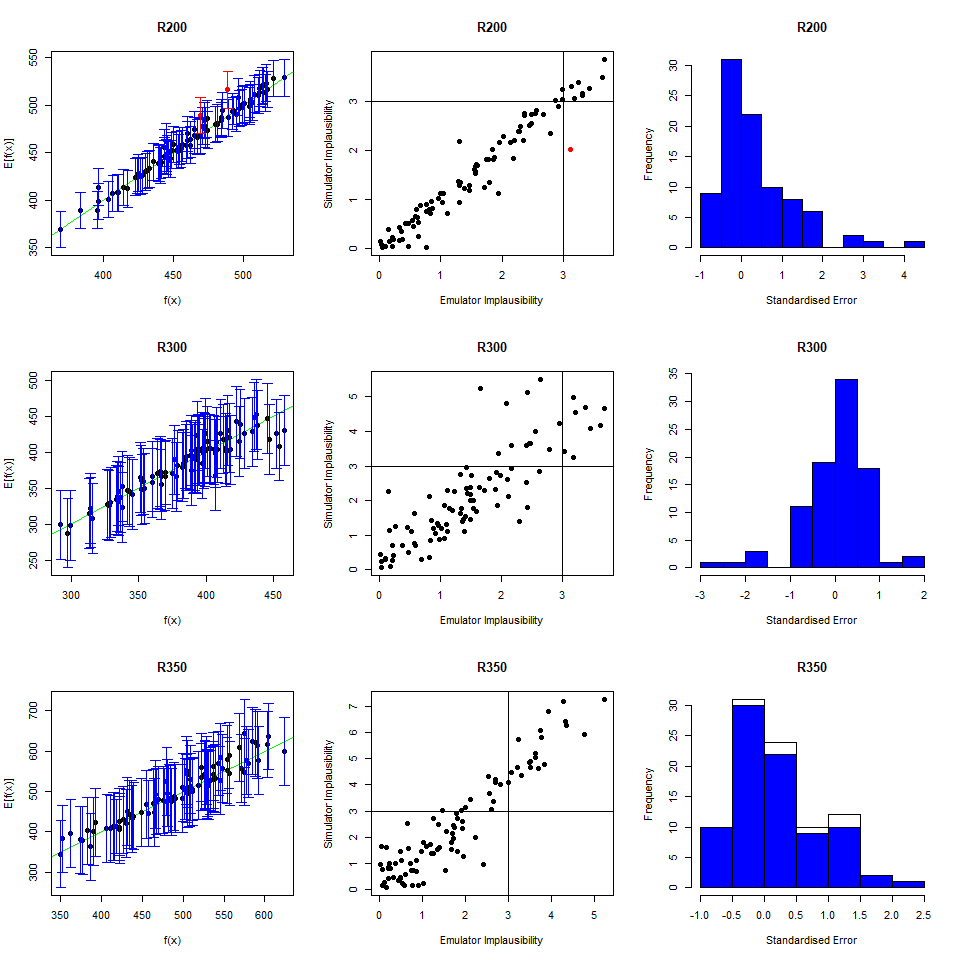
To perform a second wave of history matching and emulation we follow the same procedure as in the previous sections, with two caveats. We start by forming a dataframe wave1 using parameters sets in new_points, as we did with wave0, i.e. we run the model at new_points using the function get_results and then bind the obtained outputs to new_points. Half of wave1 should be used as the training set for the new emulators, and the other half as the validation set to evaluate the new emulators’ performance.
Now note that parameter sets in new_points tend to lie in a small region inside the original input space, since new_points contains only non-implausible points, according to the first wave emulators. The first caveat is then that it is preferable to train the new emulators only on the non-implausible region found in wave one. This can be done by setting the argument check.ranges to TRUE in the function emulator_from_data. The second caveat is that emulators from both the first and second wave need to be passed to the generate_new_design function: this is because second wave emulators tend to be rather uncertain outside of the small region of the input space where they were trained.
In the task below, you can have a go at wave 2 of the emulation and history matching process yourself.
new_points and setting check.ranges to TRUE, train new emulators. Customise them and generate new parameter sets.